
Ключевые слова: индекс чистой энергии, индекс эффективного использования топлива, оценка «зеленой» энергетики, экологическая чистота при производстве энергии, оценка углеродного следа, искусственный интеллект в энергетическом секторе, решения в области ИИ, большие языковые модели, усовершенствованные показатели энергопотребления.
Статья продолжает тему внедрения и формирования индекса чистой энергии с использованием искусственного интеллекта, авторы надеются, что представленные данные помогут сформировать методику определения стратегии устойчивого развития на глобальном и региональных уровнях, производя актуальные расчеты индекса чистой энергии самыми эффективными и современными методами (искусственный интеллект).
Большие языковые модели (БЯМ) представляют значительный потенциал для автоматизации расчетов индекса чистой энергии (ИЧЭ), позволяя учитывать множество факторов, влияющих на экологическую эффективность, но сталкиваются с рядом ограничений. Эти ограничения включают вычислительную сложность, интерпретируемость результатов и точность модели при обработке специфических данных. В частности, главная проблема ИИ: верификация и создание релевантного ответа для пользователя, который использует различные языковые модели для получения ответов на поставленный вопрос, а также сами «галлюцинации» модели. К примеру, в статье [8] авторами проводился анализ ошибочных «суждений» и результатов модели, давая определения и точную природу таких видов ошибок.
Следовательно, встает вопрос о машинном обучении искусственного интеллекта и важности качественных обучающих данных для машинного обучения, как указывается в исследованиях Devlin et al. (2019) [2], суть которого заключалась в исследованиях эффективности использованиях контекста для улучшения понимания языка, где обучение происходило на больших корпусах текстов, таких как BooksCorpus и Wikipedia. Доказывая необходимость и важность включаемых данных в модель, так как она напрямую влияет на точность и надежность моделей для получения релевантных ответов пользователю и обучаемости самой модели. Чтобы модель могла точно изучать закономерности и делать прогнозы, ее необходимо обучать на больших объемах разнообразных, точных и непредвзятых данных, которые будут отвечать требованиям пользователя. Если данные, используемые для обучения, являются некачественными или содержат неточности и систематические ошибки, прогнозы будут потенциально необъективными и могут не отвечать запросам пользователя. К примеру, в статье Brown et al. (2020) [1] обсуждаются возможности и ограничения языковых моделей, таких как GPT-3, в выполнении различных задач на основе небольшого количества примеров (few-shot learning). В контексте ошибочных суждений при неточных данных, делая вывод о том, что модели сильно зависят от данных, на которых они обучены. Если в обучающих данных содержатся ошибки или неточности, модель может интернализировать и воспроизводить эти ошибки.
Однако, как говорилось ранее, необходимо создать или использовать уже существующие инструменты работы с ИИ, чтобы оптимизировать «обучение» моделей без большого вложения капитальных и временных затрат.
Искусственный интеллект
Искусственный интеллект обучается на основе больших объемов данных с помощью алгоритмов машинного обучения, таких как нейронные сети, «деревья» решений и многое другое. К примеру, в статье [12] представлен механизм «self-attention» (самовнимание), который позволяет моделям эффективно обрабатывать зависимости между элементами входной последовательности независимо от их расстояния друг от друга или метод многоголового внимания, который позволяет модели одновременно учитывать информацию из разных подпространств представлений, улучшая способность к захвату разнообразных паттернов. Эти алгоритмы помогают ИИ обнаруживать закономерности и шаблоны в данных, делая прогнозы более точными, а решения более обоснованными.
По своей сути искусственный интеллект является лишь набором математических действий и знаков, и факт наличия такого слова, как «интеллект», описывает только способность машины к симуляции интеллекта человека, но не способность машины создавать новые данные, а только компилировать ответы на базе существующих данных в ее системе.
Процесс работы искусственного интеллекта заключается в сложении или вычитании векторов в многомерном пространстве, которые иначе называются эмбеддерами. Именно эмбеддинг используется для обработки человеческого языка или иного формата коммуникации с искусственным интеллектом. В свою очередь, ИИ формирует числовые формулировки и представления для нечисловых данных (текст, изображение и иные форматы).
Retrieval Augmented Generation (RAG)
Использование БЯМ для получения информации по расчету индекса чистой энергии осложняется возможным недостатком данных в данном конкретном случае из-за его узкой направленности, связанной с парниковыми газами и с постоянно меняющейся ситуацией в мире (курсы валют, изменения каких-либо производственных технологий и т.д.). В статье «A comprehensive survey on graph neural networks» (Johnson, 2020) [4] обсуждаются основные положения и ограничения графовых нейронных сетей (GNN), связанные с ограничениями в способности обработки динамических данных, временных данных и трудности с обучением на нестационарных данных.
В таком случае существуют 2 основных варианта решения данной проблемы:
- обучать модель с нуля,
- использование Retrieval Augmented Generation (RAG).
Учитывая особенности обучения модели с нуля, а именно – сложности формирования базы данных и тяжести обучения модели, которое может затянуться на несколько лет с затратой финансовых вложений и использования больших компьютерных мощностей, не имеет смысла в данном случае. Также стоит учитывать, что необходимо обучение модели на релевантных «золотых» ответах для получения необходимого результата по точности, которая требуется от ИИ. Следовательно, необходимо и множество «ручной работы», когда пользователь формирует запросы и определяет близость вектора к основной оси (требуемый результат).
В таком случае авторами статьи предлагается решение проблемы данной неопределенности через использование RAG, который был сформулирован командой FAIR в статье [6] в 2021 году. Данный метод работы с БЯМ характеризуется особенностью взаимодействия с искусственным интеллектом. Когда пользователь формирует конкретный вопрос/задачу и программно добавляет к своему запросу дополнительную информацию, благодаря которой языковая модель способна уже с ее помощью сформировать более полный и верный ответ/результат пользователю.
Примером использования RAG с системой промптов, в нашем контексте ИЧЭ, может служить следующее:
Пользователь формирует запрос: «Какая сейчас спотовая цена сырой нефти марки Urals?»
Система осуществляет идентификацию релевантного документа или его фрагмента (чанка), в котором содержится ответ на заданный пользователем вопрос. Процесс начинается с обработки запроса пользователя и поиска наиболее подходящих сегментов данных, которые могут содержать необходимую информацию. Эта задача включает применение сложных алгоритмов информационного поиска и методов машинного обучения для повышения точности и релевантности извлеченных данных.
Однако необходимо учитывать ограничения языковых моделей в отношении понятий, не включенных в их обучающие данные. Одним из таких понятий является «сейчас». Лингвистические модели, включая большие языковые модели (БЯМ), обучаются на обширных корпусах текстов, содержащих исторические данные до определенного момента времени. Они не имеют встроенной способности к восприятию текущего момента или обновлению своей базы знаний в реальном времени. Соответственно, модель не может предоставить точный и актуальный ответ на вопросы, требующие знания текущей информации, если эта информация не была включена в ее обучающий набор данных.
Например, если пользователь задает вопрос о текущем состоянии погодных условий или о последних новостях, языковая модель будет неспособна предоставить актуальный ответ, поскольку она не обладает механизмом обновления информации в реальном времени. Ее ответы будут ограничены временными рамками данных, на которых она была обучена. Это фундаментальное ограничение следует учитывать при использовании языковых моделей для задач, требующих актуальных и своевременных данных, какой задачей и является расчет индекса чистой энергии.
Для преодоления этого ограничения, системы могут интегрироваться с внешними источниками информации, такими как API-сервисы, предоставляющими актуальные данные. Этот гибридный подход позволяет комбинировать способности языковых моделей к обработке и генерации текста с возможностями получения и обновления актуальной информации, что значительно расширяет диапазон применений и повышает точность ответов. Однако существует и иной метод, использующий RAG, и именно он подходит в данном контексте задания задачи большой языковой модели. Если мы зададим ИИ область данных: «Рассмотри на сайтах a, b, c и т.д.» (подключение того же API через RAG) или добавим сами какой-либо объем токенов (отдельный элемент текста для упрощения работы ИИ), сообщив модели о необходимости формировать ответ из данных пользователя, то модель уже будет способна ответить верно для пользователя и «поймет» о чем идет речь и как формировать ответ.
Соответственно, при использовании конвейера Retrieval-Augmented Generation (RAG) модель формирует специфический prompt для большой языковой модели (БЯМ), который включает в себя данные пользователя, соответствующие внешние данные и инструкции, созданные RAG для направления работы БЯМ, а также формирует prompt.
В рамках RAG prompt играет ключевую роль в управлении поведением и генерацией текста БЯМ. Он направляет модель на выбор наиболее релевантных внешних данных, которые используются для дополнения или уточнения информации, полученной из внутренних баз данных модели. Это включает в себя указание на необходимость включения определенных аспектов контекста из внешних источников, что существенно улучшает качество и полноту сгенерированных ответов.
Использование RAG также включает в себя формирование инструкций для БЯМ, которые определяют, какие части данных пользователя и внешних источников следует учитывать при генерации ответа. Этот подход позволяет модели учитывать разнообразные аспекты контекста и максимально точно отвечать на запросы, что особенно важно в контексте обработки естественного языка и информационного поиска.
Таким образом, применение RAG с его специализированными prompt способствует значительному повышению эффективности и точности работы больших языковых моделей, делая их более адаптивными и реагирующими на контекст способом.
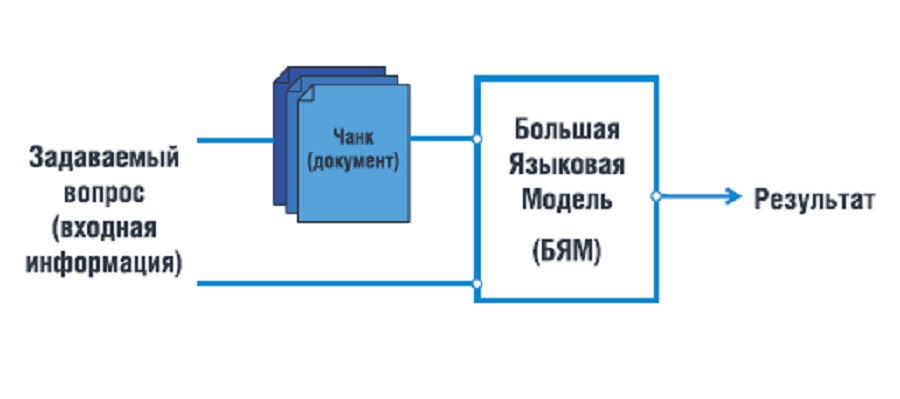
На рисунке 1 представлена упрощенная схема работы RAG.
В целом процесс при создании RAG формируется по принципу: от крупных кусков к шлифовке. Сама работа RAG может осуществляться по поиску ключевых слов или векторному, и суть метода RAG заключается в двух важных задачах NLP: извлечение релевантной информации (retrival) и генерация текста (generation). Это позволяет модели использовать внешние источники данных.
Изначальная база данных, которой владеет пользователь, нарезается на более доступные и легкие части, которые, как озвучивалось ранее, называются чанками, и с помощью эмбеддера преобразовываются в вектора.
Кодирование текста в читаемый для ИИ механизм анализируется и суммируется, создавая единую базу данных, которая хранится в самой модели. Тем самым ИИ создает из одного чанка один вектор. И уже с помощью косинусальной близости векторов между текстом запроса пользователя и чанка выбираются наиболее близкие фрагменты данных, из которых БЯМ и выстраивает свой ответ.
Также существуют иные методы поиска ответа на поставленный запрос пользователя, такие как подключение к эмбеддингам TF-IDF или алгоритм BM25.
Архитектура RAG
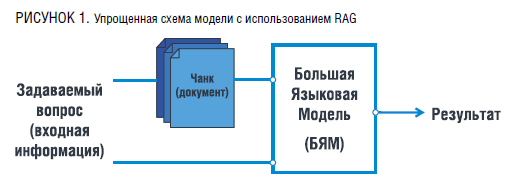
В архитектуре RAG, как было сказано ранее, используются два основных компонента: компонент извлечения информации и компонент генерации текста.
Компонентом извлечения информации является Dense Passage Retrieval (DPR), цель которого заключается в извлечении информации из больших баз данных на основе пользовательского запроса. В данном случае кодирование запроса и самих баз данных, заключенных в модели, в векторное поле происходит с помощью BART, построенном на основе трасформеров, и включает энкодеры для обработки текста.
Кодирование информации происходит следующим путем:
Входной запрос пользователя, который обозначим как q, передается через кодировщик embeddings и трансформируется в векторное представление qvec. Каждый документ (текстовый файл) di в базе данных также кодируется с помощью кодировщика, чтобы получить векторное представление dveci, что позволит модели обработать полученный формат данных и усвоить его. Косинусальное расстояние между qvec и dveci вычисляется для всех документов в базе данных, что дает модели представление о «близости» текста к запросу пользователя. Документы с наименьшим косинусным расстоянием считаются наиболее релевантными и отбираются для генерации ответа пользователю исходя из того формата запроса, что внес пользователь.
Компонентном генерации текста в модели происходит с помощью того же Sentence Transformers (SBERT) или же иного кодировщика, к примеру T5. Модель генерирует текстовый ответ, используя контекст из документов, а также иную базу данных, на которой она была обучена. Исходя из этого, ответ на запрос пользователя становится наиболее точным и полным, что и позволяет считать результат релевантным.
Также BERT (Bidirectional Encoder Representations from Transformers) [2] и BART (Bidirectional and Auto-Regressive Transformers) [14], которые являются двумя различными моделями преобразователей, разработанными для обработки естественного языка, различаются по архитектуре и применению. Из двух представленных моделей эффективнее и рациональнее использовать BART, так как BART более универсален и может быть использован как для генеративных задач (создание текста), так и для дискриминативных задач (понимание текста), что делает его подходящим для решения нашей задачи, включая обобщение текста, перевод, исправление ошибок и другие задачи, связанные с генерацией.
Однако на современном этапе развития технологий наиболее продвинутыми и точными считаются модели LLM-трансформеров и sentence-transformers, что и предлагается к применению авторами статьи.
Основными характеристиками LLM-трансформеров можно выделить большое число параметров, включающихся в систему, и сложные архитектурные решения, что позволяет им захватывать сложные зависимости и контексты в предлагаемом тексте. Данные модели используют задачу авторегрессионного моделирования (Auto-Regressive Modeling), которая значительно улучшает их возможности в генерации и переработке текстовой информации, создаваемой пользователем и для самого пользователя. Преимущества LLM-трансформеров также заключаются в их способности выполнять широкую гамму задач, сложные системы вопрос-ответ, перевод и обобщение текста с высокой степенью точности и естественности (приближая к человеческой системе языка). Благодаря своей универсальности и масштабируемости LLM-трансформеры являются предпочтительным выбором для обработки больших объемов данных и сложных языковых задач.
Sentence-transformers, в свою очередь, представляют собой модификацию моделей, таких как BERT, для создания семантических векторных представлений предложений. Эти модели специально обучены на парных задачах, таких как задачи сравнения текстов, например, Semantic Textual Similarity (STS), что позволяет им эффективно улавливать смысл целых предложений. Это значительно повышает их производительность в задачах, связанных с вычислением семантической близости между предложениями, таких как семантический поиск, кластеризация и сравнение текстов. Sentence-transformers обеспечивают более точное и интуитивное понимание текста, что делает их незаменимыми для задач, требующих глубокого семантического анализа.
Следовательно, предлагается в первую очередь использовать LLM-трансформеры и sentence-transformers, обеспечивающие более высокую точность, универсальность и качество обработки и генерации текста. Их применение делает возможным решение сложных задач обработки естественного языка, обеспечивая высокую степень точности, масштабируемости.
Генерация текста пользователю:
Извлеченные документы, которые уже преобразованы в вектора, формируют базу данных, включая вводимый пользователем запрос и чанк. В модели это можно представить как хранимую информацию в формате: D = {d1, d2, d3, …, dn}. Данная база данных объединяется с исходным запросом пользователя q для создания расширенного входа. Генеративная модель (BART или Т5) принимает расширенный вход и генерирует текстовый ответ a, составленный на базе ранее представленных текстовых файлов
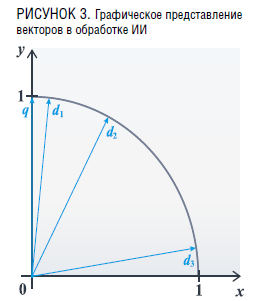
На графике 3 изображен пример векторной сходимости между вектором q и данными модели d1, d2, d3.
Нахождения следующих векторов эмбеддингов можно описать в виде текста следующим образом:
Запрос q: «Можете ли Вы сформулировать основные требования к расчету выбросов углекислого газа?»
Результат d1: «Точность данных, стандартизация методик, учет всех источников выбросов…»
Результат d3: «Иммануил Кант был рожден в восточной части Пруссии».
Решения «галлюцинаций» и ошибок модели
Помимо привычных нам неверных ответов, которые пользователь может определить самостоятельно, имея определенные знания в теме, существуют и «галлюцинации», когда модель создает ответ, который выглядит обоснованным и правдивым, однако по своей сути не имеет никакого смысла и может быть вызван различными причинами: от ошибок в структуре графов до неполноты данных [11]. Именно такой вид ошибок актуален для расчета индекса чистой энергии.
Формирование необходимых ответов и выявление «галлюцинаций» в самой модели может происходить по нескольким возможным путям:
· Проверочные вопросы (вопросы, специально разработанные для выявления слабостей или ошибок модели).
Процесс работы с моделью происходит через создание наборов вопросов, которые охватывают различные аспекты знаний, которые модель должна уметь обрабатывать, в нашем же случае вопросы могут концентрироваться на данных, связанных с СО2. В целом же вопросы могут быть разнообразными, от простых фактов до сложных аналитических задач. Ответы модели на эти вопросы тщательно анализируются самим пользователем для выявления возможных ошибок или «галлюцинаций».
Основными недостатками являются значительные усилия для создания и поддержания актуального набора проверочных вопросов от самого человека/пользователя. Откуда и выходит второй недостаток такого метода: невозможность всегда охватить все возможные случаи использования модели.
· Референсные ответы и их сравнение (заранее подготовленные правильные ответы на определенные вопросы или задачи. Они служат эталоном для оценки качества ответов, генерируемых моделью).
Изначально при настраивании модели определяются ключевые вопросы, на которые модель должна уметь отвечать. Создаются или собираются правильные ответы для этих вопросов. Ответы модели сравниваются с референсными ответами для оценки точности.
Основными недостатками может служить: ограниченость количества референсных ответов и человеческий фактор, а именно – неспособность охватить все возможные ситуации. Референсные ответы должны постоянно обновляться для обеспечения их актуальности. Также требуются значительные ресурсы для создания и поддержания референсных ответов. Модель может не учитывать контекстуальные различия между вопросами и ответами.
· Сходимость чанков (метод анализа, при котором ответы модели на один и тот же вопрос, но разделенные на разные части текстового файла (чанки), проверяются на их согласованность).
Здесь основной принцип работы заключается в формировании вопроса, когда он разбивается на несколько частей (чанков), которые подаются модели для ответа. Ответы модели на каждый чанк анализируются на предмет согласованности и точности. Сравниваются ответы на разные чанки для выявления несоответствий.
Преимуществом данного типа борьбы с ошибками служит возможность выявления скрытых ошибок и несогласованностей в ответах модели.
Однако данный тип борьбы с ошибками требует значительных вычислительных ресурсов для анализа множества чанков, что делает этот метод сложным для реализации в больших масштабах и, соответственно, трудным при реализации в расчетах индекса чистой энергии.
· Retrieval Augmented Generation Automated Scoring (RAGAS) (метод автоматической оценки производительности системы, использующий метрики для оценки качества генерации ответов с использованием RAG).
Включает в себя метрики, такие как точность контекста, контекстный отзыв, верность и релевантность ответа. Система автоматически оценивает производительность модели на основе этих метрик, сравнивая с заранее определенными стандартами. В соответствии с этим обеспечивает объективную и автоматизированную оценку производительности модели. Позволяет быстро и точно измерять качество ответов модели.
Однако при создании требует сложной настройки и калибровки метрик для обеспечения точности.
· Запрос к самой модели (метод, при котором пользователи задают модели дополнительные вопросы для проверки ее ответов и получения дополнительной информации о процессе генерации ответа).
Пользователи могут задавать модели вопросы, такие как «Почему ты так ответила?» или «Насколько достоверны результаты?» Модель предоставляет объяснения или дополнительные данные, которые помогают пользователям понять процесс генерации ответа и выявить возможные ошибки. Благодаря чему обеспечивается возможность глубокой проверки и анализа ответов модели, это помогает пользователям лучше понять процесс работы модели и выявить ошибки.
Каждый из этих методов имеет свои преимущества и недостатки. В идеале для достижения наибольшей точности и надежности модели следует комбинировать несколько методов, чтобы покрыть все возможные аспекты и выявить скрытые ошибки. Однако в контексте поставленных задач из всех перечисленных вариантов решения проблемы самыми эффективными для пользователя при расчете ИЧЭ являются RAGAS и запрос к самой БЯМ. Следовательно, необходимо подробнее остановиться на этих двух типах выявления ошибок в самой модели.
Retrieval Augmented Generation Automated Scoring (RAGAS)
RAGAS используется как инструмент для оценки конвейеров RAG. RAGAS (Retrieval-Augmented Generation Assessment Scores) представляет собой набор метрик, предназначенных для оценки производительности систем, использующих конвейеры Retrieval-Augmented Generation (RAG). Конвейеры RAG интегрируют методы информационного поиска (retrieval) с моделями генерации текста (generation), чтобы обеспечить более релевантные и информативные ответы на сложные запросы пользователей.
RAGAS представляет собой метрики с минимальной зависимостью от аннотированных данных, предоставляя информацию о производительности системы и релевантности ее ответов. В отличие от традиционных методов оценки, которые часто требуют большого количества предварительно аннотированных данных, RAGAS ориентируется на метрики, которые минимизируют эту зависимость. Это позволяет проводить оценку систем RAG более гибко и экономично. Метрики RAGAS обеспечивают всестороннюю оценку, охватывая как этап извлечения данных, так и этап генерации текста, что критически важно для комплексного анализа производительности системы.
RAGAS использует следующие метрики:
· Точность контекста (Context Precision). Эта метрика оценивает, насколько точно система извлекает релевантные фрагменты информации из базы данных или корпуса документов в ответ на запрос пользователя. Точность контекста определяется как доля извлеченных элементов, которые действительно релевантны запросу. Высокая точность контекста указывает на то, что система способна эффективно находить соответствующую информацию с минимальным количеством нерелевантных данных. Например, в статье «Dense Passage Retrieval for Open-Domain Question Answering» [5] описывается, как плотные векторные представления могут улучшить точность извлечения контекста.
· Контекстный отзыв (Context Recall). Контекстный отзыв измеряет полноту извлечения релевантной информации. Эта метрика рассчитывается как доля релевантных элементов, которые были извлечены системой, относительно общего количества релевантных элементов в базе данных. Высокий контекстный отзыв показывает, что система извлекает большую часть релевантной информации, минимизируя упущения. Работы по оптимизации отзывов, такие как «Anserini: Enabling the Use of Lucene for Information Retrieval Research» [13], подчеркивают важность высоких значений этой метрики для эффективности информационного поиска.
· Верность (Factuality). Верность оценивает точность и достоверность сгенерированного текста относительно извлеченной информации и запроса пользователя. Эта метрика важна для определения соответствия сгенерированных ответов фактическим данным. Низкая верность может указывать на тенденцию модели к генерации неверной или вводящей в заблуждение информации. В статье «Evaluating the Factual Consistency of Abstractive Text Summarization» [7] обсуждаются методы оценки верности и важность этой метрики для обеспечения надежности системы.
· Релевантность ответа (Answer Relevance). Эта метрика оценивает соответствие и полезность сгенерированного ответа запросу пользователя. Релевантность ответа учитывает, насколько хорошо ответ решает информационную потребность пользователя, включая оценку его полноты, точности и уместности. Высокая релевантность ответа показывает, что система не только точно понимает запрос, но и предоставляет полезную и качественную информацию. Метрики, подобные тем, которые обсуждаются в «BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding» [2], помогают оценивать релевантность ответов и их соответствие запросам.
Эти метрики в совокупности предоставляют глубокую и комплексную оценку производительности конвейеров RAG, позволяя выявить узкие места и направить усилия на оптимизацию системы. Это способствует созданию более эффективных и надежных систем информационного поиска и генерации текста, что критически важно в контексте требований к обработке естественного языка и взаимодействию с пользователями при расчете индекса чистой энергии.
Запрос к Большой языковой модели
Запрос к самой модели является одним из наиболее простых и эффективных методов оценки верности ответа, как указано в статье «Adaptation with Self-Evaluation to Improve Selective Prediction in LLMs» (2023) [11], где описывается эффективность применения, а также предлагается структура под названием ASPIRE, которая улучшает способность модели к самооценке своих выводов для повышения точности в задачах селективного предсказания. Модель при правильной настройке способна анализировать свои собственные ответы на вопросы, такие как: «Почему большая языковая модель (БЯМ) так ответила?» или «Насколько достоверны результаты?». Этот процесс самоанализа включает в себя возможность модели предоставлять обоснования своих ответов и степень уверенности в них, что значительно повышает прозрачность и надежность ее выводов.
Более того, модели можно задать запрос на предоставление исходной информации, на основе которой был сформирован ответ. Это включает в себя ссылки на первоисточники данных или объяснение логических шагов, использованных для построения ответа. Такой подход не только способствует проверке точности и достоверности сгенерированных ответов, но и позволяет пользователям лучше понять процесс генерации ответа и выявить возможные ошибки или искажения.
Дополнительно методика prompt engineering служит важным инструментом для повышения эффективности БЯМ. Суть этой методики заключается в тщательно продуманной формулировке запросов (prompts), которые управляют поведением модели для получения необходимых результатов без изменения ее внутренней архитектуры или параметров. Prompt engineering позволяет оптимизировать взаимодействие с моделью, фокусируясь на конкретных задачах и снижая вероятность генерации нерелевантной или недостоверной информации.
Использование продуманных prompts включает несколько аспектов:
· Контекстуализация запроса: предоставление модели максимально точной и релевантной информации для минимизации интерпретационных ошибок.
· Пошаговое руководство: разбивка сложных задач на более простые этапы, что позволяет модели последовательно решать каждый из них с большей точностью.
· Ограничение диапазона ответов: задавание таких формулировок, которые сузят возможные варианты ответов модели, что помогает избежать слишком общих или неконкретных результатов.
Применение этих стратегий в рамках prompt engineering способствует более точному и целенаправленному использованию БЯМ, позволяя достигать высоких результатов в различных областях применения – от автоматического перевода до сложного анализа данных и генерации текстов.
Такая методология, основанная на запросах к самой модели и использовании prompt engineering, открывает новые горизонты в оценке и улучшении производительности больших языковых моделей, обеспечивая более высокий уровень доверия к их результатам и более эффективное их применение в практических задачах при расчете тех или иных показателей.
Fully Homomorphic Encryption (FHE)
С одной стороны, использование возможностей БЯМ позволит во много раз упростить расчет ИЧЭ, но также существуют трудности получения информации от компаний и производств и связанных с этим рисков утечки конфиденциальной информации.
Одним из возможных решений этой проблемы является использование полностью гомоморфного шифрования (FHE) [10], которое позволяет выполнять функции с зашифрованными данными. Когда выгруженные данные из различных организаций и компаний в БЯМ шифруются алгоритмом внутри самой системы модели и уже невозможны к прочтению сторонними пользователями. Однако при запросе от пользователя по заданному вопросу возможно получение ответа, и только этот ответ способен увидеть сам пользователь без нарушения коммерческой конфиденциальности.
Полностью гомоморфное шифрование (FHE) представляет собой революционное достижение в области криптографии, позволяющее выполнять вычисления над зашифрованными данными без их расшифровки. Эта возможность решает важные проблемы конфиденциальности данных и безопасности в области облачных вычислений и других сценариях, где требуется обработка чувствительной информации в ненадежных средах.
FHE достигает своей функциональности благодаря сложному взаимодействию математических техник, включая алгебраические структуры, такие как решетки, теория чисел и полиномиальные кольца. Основной принцип FHE заключается в возможности выполнять произвольные вычисления непосредственно над зашифрованными данными, сохраняя конфиденциальность на протяжении всего процесса вычислений. Это достигается путем обеспечения того, что как операции сложения, так и умножения над зашифрованными данными дают результаты, которые являются значимыми и согласованными при расшифровке.
Практическая реализация FHE включает несколько ключевых компонентов и методов:
- Схемы гомоморфного шифрования. Различные схемы, такие как исходная схема Гентри и последующие улучшения, например схема Бракерски-Гентри-Вайкунтанатан (BGV) и схема Фана-Веркотерена (FV), предоставляют различные компромиссы между эффективностью и безопасностью. Эти схемы позволяют выполнять различные типы вычислений гомоморфно с различными уровнями вычислительной и коммуникационной нагрузки.
- Выбор параметров. Схемы FHE требуют тщательного выбора параметров, таких как модуль, параметры шума и размеры ключей, для балансировки безопасности и эффективности. Эти параметры влияют на уровень защиты от различных атак (например, атаки на основе решеток) и производительность гомоморфных операций.
- Управление шумом. Во время гомоморфных вычислений шум накапливается из-за процесса шифрования. Техники, такие как переключение модуля и релинейзация, используются для управления и уменьшения шума, обеспечивая тем самым правильность результатов вычислений.
- Сценарии применения. FHE применяется в сценариях, где конфиденциальность данных играет ключевую роль, таких как безопасный аутсорсинг вычислений ненадежным сервером, конфиденциальное машинное обучение, безопасные вычисления между несколькими участниками и зашифрованный поиск данных. Эти приложения используют способность FHE выполнять вычисления над зашифрованными данными при сохранении конфиденциальности информации.
- Проблемы и направления развития. Несмотря на свои преимущества, FHE сталкивается с проблемами, такими как высокие вычислительные затраты, значительное увеличение размера шифротекста и ограниченная масштабируемость для сложных вычислений. Текущие исследования направлены на решение этих проблем через оптимизацию алгоритмов, аппаратных ускорителей и новых криптографических техник.
В заключение отметим, что FHE представляет собой важное достижение в области криптографии, предлагая трансформационный подход к защите данных путем возможности выполнения вычислений над зашифрованными данными. Его дальнейшее развитие и внедрение обещают значительно усилить защиту конфиденциальности в мире, где данные играют все более важную роль.
Выводы
Представленные в данной статье решения направлены на устранение ограничений, связанных с применением больших языковых моделей для расчета индекса чистой энергии. Внедрение таких подходов обеспечит:
· Эффективное использование ИЧЭ с минимальными временными и финансовыми затратами, позволяя оценивать эффективность различных видов топлива с учетом экологических показателей.
· Возможность интеграции БЯМ без необходимости их переобучения, что упрощает и ускоряет внедрение моделей в практическую деятельность.
· Улучшение точности и актуальности ответов за счет методов, таких как Retrieval Augmented Generation (RAG), которые дополняют модели релевантными внешними данными.
· Снижение вероятности ошибок и «галлюцинаций», что делает расчеты ИЧЭ более надежными и достоверными.
· Применение полностью гомоморфного шифрования (FHE) для защиты конфиденциальных данных, что позволяет выполнять расчеты с гарантией сохранности коммерческой информации.
Внедрение данных методов и подходов значительно повысит точность, надежность и безопасность в расчете индекса чистой энергии, способствуя эффективному развитию методики определения стратегии устойчивого развития.
Литература
1. Brown, T. B., et al. (2020). Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165.
2. Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
3. Johnson, D. (2020). A comprehensive survey on graph neural networks. arXiv preprint arXiv:2001.05042.
4. Johnson, R. (2020). A comprehensive survey on graph neural networks. arXiv preprint arXiv:2001.05088.
5. Kipf, T. N., & Welling, M. (2017). Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907.
6. Lewis, P., et al. (2021). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv preprint arXiv:2005.11401.
7. Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards real-time object detection with region proposal networks. Advances in neural information processing systems.
8. Ruder, S., & Bingel, J. (2017). Learning what to share between loosely related tasks. arXiv preprint arXiv:1705.07245.
9. Stacey, A., Feng, S., and Wallace, B. (2023). Adaptation with Self-Evaluation to Improve Selective Prediction in LLMs. arXiv preprint arXiv:2305.01234.
10. Vaswani, A., et al. (2017). Attention is All You Need. arXiv preprint arXiv:1706.03762.
11. Karpukhin, Vladimir, et al. «Dense Passage Retrieval for Open-Domain Question Answering». arXiv preprint arXiv:2004.04906 (2020).
12. Yang, Peilin, et al. «Anserini: Enabling the Use of Lucene for Information Retrieval Research». Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2017.
13. Kryściński, Wojciech, et al. «Evaluating the Factual Consistency of Abstractive Text Summarization». arXiv preprint arXiv:1910.12840 (2019).
14. Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., ... & Zettlemoyer, L. (2019). BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv preprint arXiv:1910.13461.



