

Разработка моделей процессов гидрооблагораживания нефтяных фракций является важной задачей для возможности прогнозирования выхода продуктов и планирования последующего экономического эффекта. Сегодня существует несколько сред моделирования с помощью которых можно успешно выполнить данную задачу. Примерами таких сред являются продукты компаний ASPEN и Honeywell. Данные системы позволяют с высокой точностью проектировать модели любых нефтехимических и нефтеперерабатывающих процессов. Построение таких моделей крайне затратное, оно не может быть выполнено с высокой точностью за короткое время и требует от пользователя глубоких познаний. Из-за этого, рационально использовать модели машинного обучения, позволяющие существенно снизить время и ресурсозатратность перестроения модели: такие модели имеют низкий порог вхождения и могут быть переобучены оператором.
Постановка задачи
Ставится задача создания цифрового двойника процесса гидрооблагораживания, позволяющего точно оценивать показатели качества процесса:
-
остаточное содержание серы в продуктах;
-
выход гидроочищенного ДТ;
-
выход бензина;
-
выход аммиака;
-
выход сероводорода;
-
выход воды;
-
выход УВ газа;
- конечное давление и температура.
- должна присутствовать возможность моделирования констант скоростей реакций при заданном катализаторе и их оптимизации под фактический выход продуктов с установки;
- модель должна позволять оценивать качество ведения процесса в реальном времени в статике.
Схема превращений формализованных групп серосодержащих соединений представлена следующим образом:

Рис. 1. Схема превращений серосодержащих соединений
В основу моделирования процесса положены следующие кинетические реакции:

Исходные данные для решения приведенной выше системы были взяты с экспериментальных данных установки облагораживания, а также данных режимных листов, включающих следующие данные: время работы установки в днях, начальная температура процесса в градусах Цельсия и перепад давления в МПа. Данные с режимных листов лежат в основе прогнозирования дезактивации катализатора.
Альтернативная модель, используемая для сравнения, была построена в среде Honeywell UniSim Design:

Рис. 2 ‑ Схема процесса ГО ДТ в программе UniSim Design
Для обеспечения требований к гидроочищенному ДТ по температуре вспышки и содержанию сероводорода большое значение имеет правильно подобранный режим стабилизационной колонны. Рекомендуемый режим представлен в таблице 1.
Таблица 1 ‑ Рекомендуемый режим стабилизационной колонны ГО ДТ
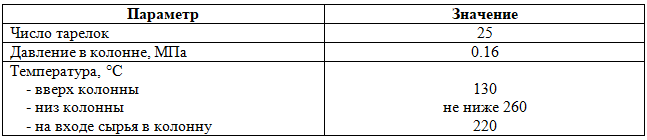
Колонна стабилизации рассчитывалась при параметрах, близких к рекомендуемым.
Для того чтобы сделать вывод о состоянии катализатора, необходимо решить задачу прогнозирования времени работы установки по вектору относительной активности с использованием модели анализатора в виде:

В основе решения задачи прогнозирования активности катализатора использовался алгоритм “Случайного Леса” (англ. Random Forest). Внутренняя компонента fi представляет собой дерево принятия решений, которое вычисляет значение относительной активности катализатора. В качестве ответа принимается усредненное значение из заданного набора деревьев (рис. 3).
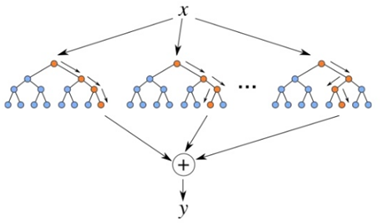
Рис. 3. Структура модели “Случайный Лес”
В основе второй прогнозирующей модели был принят алгоритм стохастического градиентного спуска, построение весовой матрицы которого выглядит следующим образом:

Для оценки точности моделей использовался коэффициент детерминации:

Модель для расчета качества продуктов использует экспериментальные данные о начальной температуре сырья в градусах Цельсия, начальном давлении в МПа, расходе дизельного топлива (ДТ) в килограммах в час и расходе водородосодержащего газа в килограммах в час. Модель представляет собой LSTM-нейронную сеть, которая состоит из пяти слоев по сто нейронов каждый, чередующихся с «dropout» слоями, а также слоя-декодировщика из ста классических нейронов с сигмоидальной функцией активации. Архитектура сети описывается следующей формулой:

В качестве тестовой и валидационной выборок выбраны последние 25% и 5% от всех данных соответственно. Обучение проводилось на временном тренде из 3000 временных точек.
В качестве критерия качества LSTM-сети использовалась логарифмическое среднее квадратическое отклонение - "lmse" (рис. 4).
Кроме того, скорость обучения подстраивалась по следующей схеме: в конце каждой эпохи обучения рассчитывается функция потерь (lmse) для текущей эпохи; каждый раз она сравнивается с сохраненным значением функции потерь на предыдущей эпохе; если эта разность по меньше чем заданное число или отрицательна, то скорость обучения делится на 10: алгоритм перестает существенно улучшать веса модели; иначе скорость обучения умножается на 10; при этом, такое изменение происходит только каждые n эпох, где n в данном эксперименте задавалось равным 10. Изменение скорости обучения изображено на рис. 5. Можно видеть, что большую часть времени скорость оставалась исходной, и только в момент, когда обучение на рис. 4 практически завершилось стала уменьшаться.

а
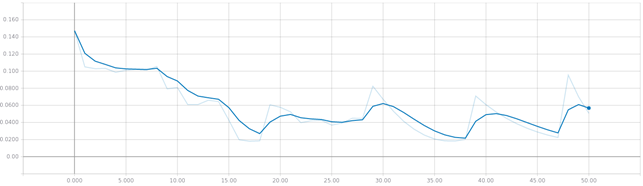
б
а - на обучающей выборке; б - на валидационной выборке;
Рис. 4 - Кривая обучения для LSTM-сети для логарифмической средней квадратической ошибки по итерациям

Рис. 5 - Кривая изменения скорости обучения по итерациям
Для предотвращения переобучения, использовался алгоритм раннего останова: каждую эпоху рассчитывается lmse для текущей эпохи и для валидации, которая проводится каждую эпоху после завершения обучения; если абсолютное значение разности между этими величинами превышает заданное (с учетом того, что изначально они находятся далеко друг от друга и ни разу не пересекались), то обучение продолжается; иначе, обучение останавливается на текущей эпохе.
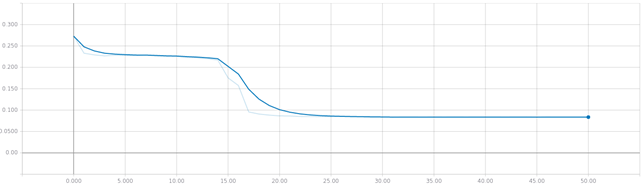
а

б
а - на обучающей выборке; б - на валидационной выборке;
Рис. 6 - Кривая обучения для LSTM-сети для средней квадратической ошибки по итерациям
Результаты
На основе приведенных выше зависимостей был построен цифровой двойник на языке программирования Python 3.5. Был проведен эксперимент на установке гидрооблагораживания дизельной фракции, результаты которого сравнивались с тремя видами моделей: моделью в среде Honeywel UniSim Design, кинетической моделью и нейронной сетью LSTM. Сравнительная таблица экспериментальных данных с результатами полученных моделей представлена в таблице 2:
Таблица 2 ‑ Результаты моделирования

Наилучшие результаты при обучении моделей были получены при следующих параметрах:
LSTM:
-
Количество итераций обучения: 10000
- Эффективное количество итераций (пройдено): 51
-
Количество нейронов в каждом слое: 100
-
Количество слоев: 5
-
Тип катализатора: ГДК-202
-
-
Коэффициент детерминации: 0.879
Случайный лес:
-
Количество деревьев: 200
-
Максимальная глубина дерева: неограничена
-
Минимальное разделение выборки: 2
-
Минимальное количество признаков в листе: 1
-
Тип катализатора: ГДК-202
-
Коэффициент детерминации: 0.785.
Эксперимент с моделью, использующий в качестве оптимизатора алгоритм стохастического градиентного спуска дал плохие результаты (R < 0) и был исключен из финальной версии модели.
В эксперименте с сетью LSTM точность модели по результатам обучения составила 75%.
Выводы
В результате было получено три модели, которые достаточно точно описывают процесс гидрооблагораживания фракции ДТ. Более точные результаты обеспечит использование кинетической модели, учитывающей разные типы катализаторов, а также возможность оптимизации констант скоростей под условия реального процесса. В случае необходимости экспресс оценки процесса (остаточное содержание серы и количество очищенной фракции ДТ), в зависимости от входных параметров (состава сырья, температуры и давления) целесообразно использовать модель, использующую LSTM нейронную сеть в качестве своей архитектуры. Полученный коэффициент детерминации сравнительная оценка с экспериментов подтверждают её эффективность. В случае предсказания активности катализатора, коэффициент детерминации несколько ниже, чем в модели LSTM. Применение данной модели прогнозирует лишь примерное время работы установки. Прежде всего это связано со сложной природой катализаторов и ограниченностью обучающего набора данных. Для улучшения качества обучения предсказания дезактивации необходимо расширить исходные выборку данными о составе и свойствах катализатора во времени.
Литература
1. Борзов А.Н. Моделирование и управление процессом гидроочистки дизельного топлива. Диссертация. – СПб: СПбГТИ(ТУ), 2005. – 219 с.
2. Gers F.A., Schmidhuber J., Cummins F. Learning to Forget: Continual Prediction with LSTM // Neural Computation. 2000. Vol. 12, № 10. P. 2451–2471
3. Gal Y., Ghahramani Z. A Theoretically Grounded Application of Dropout in Recurrent Neural Networks // arXiv:1512.05287 [stat]. 2015
4. Losses - Keras Documentation [Electronic resource]. URL: https://keras.io/losses/#mean_squared_logarithmic_error (accessed: 15.11.2018)
5. tf.keras.callbacks.ReduceLROnPlateau [Electronic resource] // TensorFlow. URL: https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/ReduceLROnPlateau




